

Turn the Web into Clean Data for AI
Built to power the Web's second user, Olostep is the best web search, scraping and crawling API for AI
-
 Start "research YC" workflow
Start "research YC" workflow -
 Automate brand protection
Automate brand protection -
 Research donors in NYC
Research donors in NYC Find local businesses
Find local businesses -
 Analyze brand visibility
Analyze brand visibility


· Parsers - structured data
· Data router
· Automation engine
· Click, fill forms
· Distributed infra
· Map/Crawl
· VM sandboxes
· Batches API
{
"id": "request_56is5c9gyw",
"created": 1317322740,
"result": {
"markdown_content": "# Ex", "json_content": {}
"html_content": "<DOC>"
}
}
Trusted by the best startups in the world


...and many more
Diagonal Sections
Using the rotation transform is how you might think to do it but I think skew is the way to go!
One API to Automate Web Data
Search, scrape, structure and monitor the whole web with one
API key. Reliable, cost-effective, scalable. Handling Billions of requests
Built for Developers
Object-oriented API, native Python and NodeJS SDK clients,
metadata support, webhook events, easy to try and easy to scale
Get clean data from any URL
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6result = client.scrapes.create(
7 url_to_scrape="https://en.wikipedia.org/wiki/Alexander_the_Great",
8 formats=["markdown", "html"],
9)
10
11print(result.markdown_content)
12print(result.html_content)1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const result = await client.scrapes.create({
7 url: 'https://en.wikipedia.org/wiki/Alexander_the_Great',
8 formats: ['markdown', 'html'],
9})
10
11console.log(result.markdown_content)
12console.log(result.html_content)1curl -s -X POST "https://api.olostep.com/v1/scrapes" \
2 -H "Authorization: Bearer <YOUR_API_KEY>" \
3 -H "Content-Type: application/json" \
4 -d '{
5 "url_to_scrape": "https://en.wikipedia.org/wiki/Alexander_the_Great",
6 "formats": ["markdown", "html"]
7 }'Crawl all the subpages
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6crawl = client.crawls.create(
7 start_url="https://olostep.com",
8 max_pages=100,
9 include_urls=["/**"],
10 exclude_urls=["/collections/**"],
11 include_external=False,
12)
13
14print(crawl.id, crawl.status)
15
16# Wait for completion and iterate pages
17for page in crawl.pages():
18 print(page.url)
19 content = page.retrieve(["markdown"])
20 print(content.markdown_content[:200])1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const crawl = await client.crawls.create({
7 url: 'https://olostep.com',
8 maxPages: 100,
9 includeUrls: ['/**'],
10 excludeUrls: ['/collections/**'],
11 includeExternal: false,
12})
13
14console.log(crawl.id, crawl.status)
15
16// Wait for completion and iterate pages
17for await (const page of crawl.pages()) {
18 console.log(page.url)
19 const content = await client.retrieve({ retrieveId: page.retrieve_id, formats: ['markdown'] })
20 console.log(content.markdown_content.slice(0, 200))
21}1# Start crawl
2curl -s -X POST "https://api.olostep.com/v1/crawls" \
3 -H "Authorization: Bearer <YOUR_API_KEY>" \
4 -H "Content-Type: application/json" \
5 -d '{
6 "start_url": "https://olostep.com",
7 "max_pages": 100,
8 "include_urls": ["/**"],
9 "exclude_urls": ["/collections/**"],
10 "include_external": false
11 }'
12
13# Check status (replace <CRAWL_ID>)
14curl -s "https://api.olostep.com/v1/crawls/<CRAWL_ID>" \
15 -H "Authorization: Bearer <YOUR_API_KEY>"
16
17# Get pages (replace <CRAWL_ID>)
18curl -s "https://api.olostep.com/v1/crawls/<CRAWL_ID>/pages" \
19 -H "Authorization: Bearer <YOUR_API_KEY>"
20
21# Retrieve content (replace <RETRIEVE_ID>)
22curl -s -G "https://api.olostep.com/v1/retrieve" \
23 -H "Authorization: Bearer <YOUR_API_KEY>" \
24 --data-urlencode "retrieve_id=<RETRIEVE_ID>" \
25 --data-urlencode "formats=markdown"Get all the URLs on a website
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6sitemap = client.maps.create(
7 url="https://docs.olostep.com",
8 include_urls=["/features/**"],
9 top_n=100,
10)
11
12print(f"Map ID: {sitemap.id}")
13
14# Iterate all URLs (handles pagination automatically)
15for url in sitemap.urls():
16 print(url)1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const map = await client.maps.create({
7 url: 'https://docs.olostep.com',
8 includeUrls: ['/features/**'],
9 topN: 100,
10})
11
12console.log(`Map ID: ${map.id}`)
13
14// Iterate all URLs (handles pagination automatically)
15for await (const url of map.urls()) {
16 console.log(url)
17}1curl -s -X POST "https://api.olostep.com/v1/maps" \
2 -H "Authorization: Bearer <YOUR_API_KEY>" \
3 -H "Content-Type: application/json" \
4 -d '{
5 "url": "https://docs.olostep.com",
6 "include_urls": ["/features/**"],
7 "top_n": 100
8 }'Process up to 10k URLs in one batch. Get results in 5-8 mins
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6batch = client.batches.create(
7 urls=[
8 {"custom_id": "item-1", "url": "https://www.google.com/search?q=stripe&gl=us&hl=en"},
9 {"custom_id": "item-2", "url": "https://www.google.com/search?q=paddle&gl=us&hl=en"},
10 ],
11 parser="@olostep/google-search",
12)
13
14print(batch.id, batch.status)
15
16# Wait and iterate results (auto-waits for completion)
17for item in batch.items():
18 content = item.retrieve(["json"])
19 print(item.url, item.custom_id)
20 print(content.json_content)1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const batch = await client.batches.create([
7 { url: 'https://www.google.com/search?q=stripe&gl=us&hl=en', customId: 'item-1' },
8 { url: 'https://www.google.com/search?q=paddle&gl=us&hl=en', customId: 'item-2' },
9], {
10 parser: '@olostep/google-search',
11})
12
13console.log(batch.id, batch.total_urls)
14
15// Wait and iterate results (auto-waits for completion)
16for await (const item of batch.items()) {
17 const content = await item.retrieve(['json'])
18 console.log(item.url, item.custom_id)
19 console.log(content.json_content)
20}1curl -s -X POST "https://api.olostep.com/v1/batches" \
2 -H "Authorization: Bearer <YOUR_API_KEY>" \
3 -H "Content-Type: application/json" \
4 -d '{
5 "items": [
6 {"custom_id": "item-1", "url": "https://www.google.com/search?q=stripe&gl=us&hl=en"},
7 {"custom_id": "item-2", "url": "https://www.google.com/search?q=paddle&gl=us&hl=en"}
8 ],
9 "parser": {"id": "@olostep/google-search"}
10 }'Semantically search the Web
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6search = client.searches.create("Latest updates with SpaceX")
7
8print(search.id, len(search.links))1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const search = await client.searches.create('Latest updates with SpaceX')
7
8console.log(search.id, search.links.length)1curl -s -X POST "https://api.olostep.com/v1/searches" \
2 -H "Authorization: Bearer <YOUR_API_KEY>" \
3 -H "Content-Type: application/json" \
4 -d '{
5 "query": "Latest updates with SpaceX"
6 }'Get answers from the Web
1# pip install olostep
2from olostep import Olostep
3
4client = Olostep(api_key="YOUR_REAL_KEY")
5
6answer = client.answers.create(
7 task="What does Olostep do and what is its core offering?",
8 json_format={"company": "", "what_it_does": "", "core_offering": ""},
9)
10
11print(answer.json_content)
12print(answer.sources)1// npm i olostep
2import Olostep from 'olostep'
3
4const client = new Olostep({ apiKey: 'YOUR_REAL_KEY' })
5
6const answer = await client.answers.create({
7 task: 'What does Olostep do and what is its core offering?',
8 jsonFormat: { company: '', what_it_does: '', core_offering: '' },
9})
10
11console.log(answer.json_content)
12console.log(answer.sources)1curl -s -X POST "https://api.olostep.com/v1/answers" \
2 -H "Authorization: Bearer <YOUR_API_KEY>" \
3 -H "Content-Type: application/json" \
4 -d '{
5 "task": "What does Olostep do and what is its core offering?",
6 "json": {"company": "", "what_it_does": "", "core_offering": ""}
7 }'Monitor pages on a schedule and get change alerts
1import requests
2import json
3
4API_KEY = "<YOUR_API_KEY>"
5API_URL = "https://api.olostep.com/v1"
6
7# Create a monitor
8payload = {
9 "query": "Alert me when Tesla stock price is above $500",
10 "frequency": "every hour",
11 "email": "alerts@example.com"
12}
13
14headers = {
15 "Authorization": f"Bearer {API_KEY}",
16 "Content-Type": "application/json"
17}
18
19response = requests.post(f"{API_URL}/monitors", headers=headers, json=payload)
20monitor = response.json()
21monitor_id = monitor['id']
22
23print(f"Monitor created: {monitor_id}")
24print(f"Status: {monitor['status']}")
25
26# List all monitors
27monitors = requests.get(f"{API_URL}/monitors", headers=headers).json()
28for m in monitors['monitors']:
29 print(f"{m['id']}: {m['url']} ({m['frequency']})")
30
31# Get monitor details
32details = requests.get(f"{API_URL}/monitors/{monitor_id}", headers=headers).json()
33print(json.dumps(details, indent=2))
34
35# Delete a monitor
36requests.delete(f"{API_URL}/monitors/{monitor_id}", headers=headers)
37print(f"Monitor {monitor_id} deleted")1const API_URL = 'https://api.olostep.com/v1'
2const headers = {
3 'Authorization': 'Bearer <YOUR_API_KEY>',
4 'Content-Type': 'application/json'
5}
6
7// Create a monitor
8const res = await fetch(`${API_URL}/monitors`, {
9 method: 'POST',
10 headers,
11 body: JSON.stringify({
12 query: 'Alert me when Tesla stock price is above $500',
13 frequency: 'every hour',
14 email: 'alerts@example.com'
15 })
16})
17
18const monitor = await res.json()
19console.log(`Monitor created: ${monitor.id}`)
20console.log(`Status: ${monitor.status}`)
21
22// List all monitors
23const monitors = await fetch(`${API_URL}/monitors`, { headers }).then(r => r.json())
24monitors.monitors.forEach(m => console.log(`${m.id}: ${m.url} (${m.frequency})`))
25
26// Get monitor details
27const details = await fetch(`${API_URL}/monitors/${monitor.id}`, { headers }).then(r => r.json())
28console.log(details)
29
30// Delete a monitor
31await fetch(`${API_URL}/monitors/${monitor.id}`, { method: 'DELETE', headers })
32console.log(`Monitor ${monitor.id} deleted`)1# Create a monitor
2curl -s -X POST "https://api.olostep.com/v1/monitors" \
3 -H "Authorization: Bearer <YOUR_API_KEY>" \
4 -H "Content-Type: application/json" \
5 -d '{
6 "query": "Track changes in product pricing and stock information",
7 "url": "https://example.com/products/widget-pro",
8 "frequency": "daily",
9 "email": "alerts@example.com"
10 }'
11
12# List all monitors
13curl -s "https://api.olostep.com/v1/monitors" \
14 -H "Authorization: Bearer <YOUR_API_KEY>"
15
16# Get monitor details (replace <MONITOR_ID>)
17curl -s "https://api.olostep.com/v1/monitors/<MONITOR_ID>" \
18 -H "Authorization: Bearer <YOUR_API_KEY>"
19
20# Delete a monitor (replace <MONITOR_ID>)
21curl -s -X DELETE "https://api.olostep.com/v1/monitors/<MONITOR_ID>" \
22 -H "Authorization: Bearer <YOUR_API_KEY>"Turn any URL into LLM-ready Markdown, HTML, screenshots, PDFs, or structured JSON. Handle JS-rendered pages, actions, and extraction workflows without maintaining browsers, proxies, or brittle scrapers.
Crawl websites at scale, collect content from subpages, control depth and URL patterns, and retrieve clean HTML or Markdown for indexing, enrichment, RAG, and AI workflows.
Discover every URL on a website using sitemaps and on-page links. Filter by path patterns, paginate large results, and prepare clean URL lists for SEO, crawls, and batches.
Process up to 10k concurrent URLs in a single batch in 5-8 mins to get clean web data and aggregate content. Run many batches in parallel to scale to millions of concurrent requests.
Ask natural-language questions and get AI-generated answers grounded in web sources. Return validated data in the JSON shape you want, with NOT_FOUND when facts cannot be verified.
Create scheduled web monitors from natural-language instructions. Track for changes on a single page or across the web, deltas, extract structured insights, and get chance notifications by email, webhook, or SMS.
Turn recurring website extraction into fast, cost-efficient structured JSON. Use pre-built parsers or create custom parsers for deterministic data pipelines. Use in conjunction with scrapes, crawls, and batches.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec velit dolor, malesuada non leo ut, mattis maximus sem








Access clean, structured data that matters most to you, when it matters the most. Power search, deep resarch, AI Agents and your applications.
Data tailored to your industry
See how Olostep powers AI platforms, sales lead enrichment, deep research, competitive intelligence, and SEO teams with one API.
Deep Search
Access custom, hyper-specialized B2B indexes for your industry to search and extract comprehensive data beyond what general web indexes cover
Add Enrichment
Recruiting
Identify, research, and validate candidates faster with intelligence and data aggregated from top-quality profiles and specialist web sources.
Recruiting Pipeline
Power AI applications
Get clean, structured data from any website as markdown, html, screenshot, etc. to power your AI application and workflows
Extract Content
Monitor the Web
Monitor any webpage for DOM changes, stock availability, price changes, job openings or fresh content. Run automatically on a schedule and get alerted
Monitor Webpage
Automate data pipelines
Automate complex data pipelines with the /agents endpoint through natural language prompts. You can also pass your own internal knowledge as context
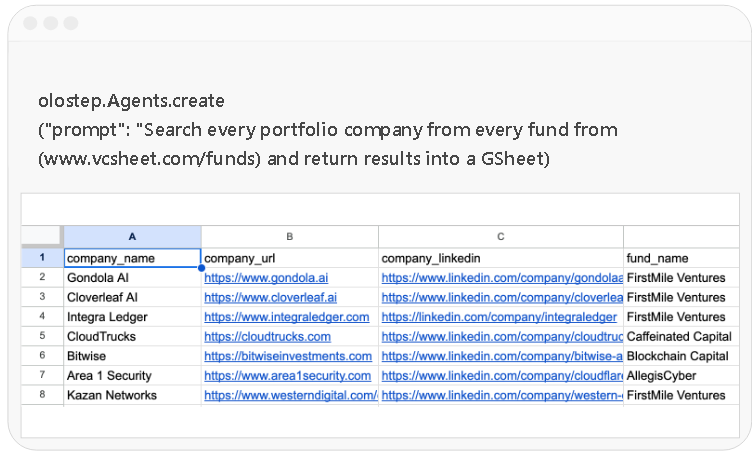
olostep.Agents.create("prompt": "Search every portfolio company from every fund from (www.vcsheet.com/funds) and return results into a GSheet")
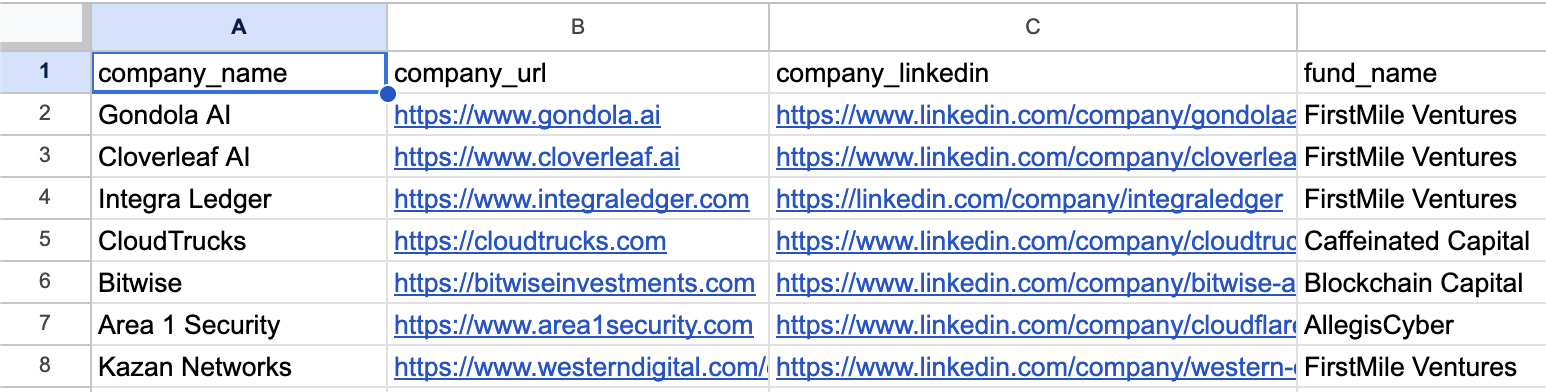
Automate complex data pipelines with the /agents endpoint through natural language prompts. You can also pass your own internal knowledge as context

Deep research agents
Enable your agent to conduct deep research on large Web datasets.

Spreadsheet enrichment
Get real-time web data to enrich your spreadsheets and analyze data.

Lead generation
Research, enrich, validate and analyze leads. Enhance your sales data
Vertical AI search
Build industry specific search engines to turn data into an actionable resource.

AI Brand visibility
Monitor brands to help improve their AI visibility (Answer Engine Optimization).

Agentic Web automations
Enable AI Agents to automate tasks on the Web: fill forms, click on buttons, etc.
Pricing that Makes Sense
We want you to be able to build a business on top of Olostep.
Start for free. Scale with no worries.
Most cost-effective web data API on the market
Top-ups
Have spiky usage or don't like subscriptions?
You can buy credit packs. They are valid for 6 months.
Credit pack
Credit pack
Credit pack
Enterprise
Trusted by Amazing Teams Building the Future of AI
Trusted by world-class teams
Discover why the best teams in the world choose Olostep.
Read more customer stories →

Olostep is the best!!! We automated entire data pipelines with just a prompt

Olostep has become the default Web Layer infrastructure for our company

Olostep works like a charm! And your customer service is exceptional

Olostep lets us turn any website into an API. Great product, great people

I highly recommend Olostep, great product!

We verify coupon codes at scale. Love Olostep. It works on any e-commerce

Olostep is the best API to search, extract, and structure data from the Web. Happy to be customers

We use /batches combined with parsers and it's magical how we can get structured data at large scale

Olostep allowed us to search and structure events data across the Web

Reliable and cost-effective API for working with data. Congrats on the cool product
Connect Olostep to Your AI Stack
Official Olostep integrations. Add web scraping,
crawling and AI-powered search to any tool in your stack.






























Connect with your AI agents
A deterministic, repeatable, controllable pipeline that automates any web research workflow and pipeline exactly as you described it.






Use the Olostep CLI
Map, scrape, crawl, batch process, and generate answers directly from your terminal, with clean JSON output built for scripts, CI pipelines and AI agents.
npx -y olostep-cli@latest --help
Add Olostep to your MCP client
Works with any product that implements the Model Context Protocol: register Olostep once and call web tools from chat, agents, or IDEs that support MCP.
{
"mcpServers": {
"olostep-web": {
"command": "npx",
"args": ["-y", "olostep-mcp"],
"env": {
"OLOSTEP_API_KEY": "YOUR_API_KEY"
}
}
}
}
Ready to start?
Get clean data for your AI from any website with Olostep
Most cost-effective API. Built for scale
Frequently asked questions
Product & Capabilities
What is Olostep?
Olostep is a Web Data Infrastructure that helps AI teams search, crawl, scrape and structure web data through a single, developer-friendly platform. Built for modern AI workflows, it makes it easier to turn public web content into clean, structured outputs for research, enrichment and automation.
From one-off extractions to high-volume data pipelines, Olostep gives teams a reliable and scalable way to collect web data without building and maintaining complex scraping infrastructure themselves.
Olostep also includes an Agent that lets users automate research workflows and generate structured outputs using natural language prompts, making it easier to move from manual research to scalable automation.
What is a Web Data API?
A Web Data API allows developers to extract, crawl and structure data from websites at scale. It handles rendering, anti-bot protection and parsing, returning clean outputs such as JSON or HTML for use in applications, analytics or AI workflows.
Why should I use Olostep?
Olostep is reliable (99.5% uptime), cost-effective (up to 70% cheaper), scalable, and flexible to work with your existing workflows and backend. It is one of the few platforms where you can create custom parsers to return deterministic results at scale in a cost-effective way. You can request features you need, and our team will work on adding them. You can also test Olostep for free to see if it fits your use case. Get your free API keys here: https://www.olostep.com/auth/
Who should use Olostep?
Olostep is built for AI startups, developers, AI engineers, data scientists and research teams that rely on web data to power products, enrich datasets and automate workflows.
It is especially useful for teams that need to search, crawl, scrape and structure web data for use cases such as market research, website monitoring, data enrichment, historical web analysis, LLM fine-tuning and grounding AI systems with real-world data.
By returning clean, structured outputs through a single API, Olostep makes it easier to plug web data into existing backends, pipelines and AI applications.
Which websites can Olostep access/interact?
Olostep can access and interact with most publicly available websites, including those that require JavaScript rendering.
If your use case involves authentication, cookies or logged-in sessions, you can get in touch at info@olostep.com to explore supported options.
Can Olostep support my high-volume requests?
Yes, Olostep is built to handle high-volume data extraction at scale, supporting up to billions of requests per month. With features like batch processing, distributed infrastructure and scalable workflows, it is designed for both growing teams and enterprise-level use cases.
Usage & Automation
How does a Web Data API work?
A Web Data API processes requests by rendering web pages, handling anti-bot protections, extracting structured data and returning it in formats such as JSON or Markdown. This removes the need to manage scraping infrastructure manually.
What is the difference between crawling and scraping?
Crawling refers to discovering and navigating multiple pages across a website, while scraping focuses on extracting data from a specific page. A Web Data API typically supports both processes in a unified workflow.
What formats does Olostep return results in?
Most Web Data APIs return data in structured formats such as JSON, as well as HTML, Markdown or raw content depending on the use case. Structured outputs are commonly used for automation and AI workflows.
Can Olostep automate my data pipelines?
Yes, Olostep is designed to support automated data pipelines and research workflows on the web. With capabilities for searching, crawling, scraping, structuring data and running repeatable workflows, it can support a wide range of business and AI use cases.
If you have a specific workflow in mind, contact the team at info@olostep.com or via the Contact Sales page to discuss the best setup for your use case.
Can I extract data with a prompt?
Yes, Olostep lets you extract data using natural language prompts. If you already know the exact page you want to process, you can use the /scrapes endpoint with LLM extraction to describe the data you want returned.
For high-volume or deterministic extraction, Olostep's parsers are the better option, as they return structured JSON more consistently at scale.
For more advanced workflows, such as searching for data, navigating across pages, handling pagination or validating results, the /agents endpoint can automatically carry out multi-step extraction based on your prompt.
What is counted as a request?
One request equals one webpage or one PDF processed. We do not charge separately for bandwidth, proxies, or data usage. All infrastructure costs are included in the price per request.
Does Olostep charge for failed requests?
No, Olostep does not charge for failed requests. You are only billed for successful requests, ensuring predictable and fair usage-based pricing.
For endpoints that involve LLM processing (such as the Answers API), any underlying model costs may still apply. However, Olostep itself only charges for requests that are successfully completed.
Is web scraping legal?
Web scraping is legal in many cases, but depends on how the data is accessed and used. It is important to follow website terms of service, data privacy regulations and applicable laws when extracting web data.
Pricing & Plans
Does Olostep offer a free trial?
Yes, Olostep includes a free plan with 500 requests to help you test the API before upgrading. Paid plans start from $9/month and include 5,000 credits per month.
This gives teams a low-risk way to evaluate Olostep's reliability, scalability and cost-effectiveness before moving to higher-volume usage.
Can I switch plans after signing up?
Yes, you can switch plans at any time. Plans are pro-rated, meaning any unused value from your current plan is carried over to your new plan.
This ensures you don't pay twice for usage you've already covered, giving you flexibility as your needs grow.
Can I ask for a refund if I don't use it?
Yes. If you're not satisfied with the Olostep API or it doesn't end up being useful for your use case, you can email info@olostep.com to request a refund.
If you cancel after a period of non-use, Olostep can also refund the unused portion of your plan where applicable.
How can I pay?
You can pay through Stripe Payment Links. To access billing, you must be logged in to your Olostep account. Go to your dashboard, navigate to Billing & Invoices, click Manage on Stripe, and add your card details. Once your card is added, you’re good to go.
