
Firecrawl vs Olostep: A Detailed Comparison for Scalable, LLM-Ready Web Scraping
Web scraping has evolved from brittle selector-based bots to intelligent data pipelines geared for AI and analytics. In this new landscape, modern scrapers must not only extract data but also deliver results that are scalable, reliable, concurrent, and ready for Large Language Models (LLMs).
Two prominent contenders in this space are Firecrawl and Olostep, each with a unique paradigm and strengths. Below, we examine how they compare across fundamental dimensions.
1. Overview: What Are They?
Olostep
Olostep is a web data API designed for AI and research workflows, offering endpoints for scraping, crawling, mapping, batch jobs, and even agent-style automation. It emphasizes simplicity, reliability, and cost-effective scalability for high-volume data extraction.
Firecrawl
Firecrawl is an API-first, AI-powered web scraping and crawling platform built to deliver clean, structured, and LLM-ready outputs (Markdown, JSON, etc.) with minimal configuration. It emphasizes intelligent extraction over manual selectors and integrates natively with modern AI pipelines like LangChain and LlamaIndex.
2. Concurrency, Parallelism & True Batch Processing
This is where Olostep fundamentally separates itself from the rest of the market.
Olostep
Olostep offers true batch processing through its /batches endpoint, allowing customers to submit up to 10,000 URLs in a single request and receive results within 5–8 minutes.
This is not an “internally optimized loop over /scrape”. It is a first-class batch primitive, designed specifically for high-volume production workloads.
In addition:
- 500 concurrent requests on all paid plans
- Up to 5,000 concurrent requests on the $399/month plan
- Concurrency can be increased significantly for enterprise customers
This architecture is the reason Olostep customers can confidently operate at millions to hundreds of millions of requests per month.
Pros
- True batch jobs at massive scale (not pseudo-batching)
- Extremely high concurrency limits by default
- Designed for production pipelines, not scripts
Cons
- Slight learning curve for batch-based workflows
Firecrawl
Firecrawl supports asynchronous scraping and small batches, but “batch” typically means tens to at most ~100 URLs, handled internally through optimized queues.
Concurrency is intentionally limited to protect infrastructure and maintain simplicity, which works well for:
- Developers
- Prototypes
- Early-stage products
However, these limits become noticeable when workloads exceed hundreds of thousands of pages per month.
Pros
- Easy parallelism for small-to-medium workloads
- Simple async workflows
Cons
- No true large-scale batch abstraction
- Concurrency limits make large-scale production harder
3. Reliability & Anti-Blocking
Reliability is often underestimated in web scraping until systems move from experiments to production. At scale, even small differences in success rate, retry behavior, or pricing for failed requests compound into major operational and cost issues.
Olostep
Olostep is designed with production reliability as a first-class constraint. Its infrastructure includes built-in proxy rotation, CAPTCHA handling, automated retries, and full JavaScript rendering without exposing these complexities to the user.
Most importantly, Olostep delivers a ~99% success rate in real-world scraping workloads. Failed requests are handled internally and do not result in unpredictable cost spikes.
A key differentiator is pricing predictability:
- 1 credit = 1 page, regardless of whether the site is static or JavaScript-heavy
- No premium charges for JS rendering
- Reliable outcomes without developers needing to tune retries or fallback logic
Why this matters: At millions of requests per month, predictable success rates and costs are essential for maintaining healthy unit economics.
Pros
- Very high success rate (~99%)
- Strong anti-blocking and retry mechanisms are used by default
- Predictable pricing even for complex, JS-heavy sites
Cons
- Less visibility into internal retry logic (abstracted by design)
Firecrawl
Firecrawl also offers solid reliability for small to mid-scale workloads, with proxy rotation, stealth techniques, and JavaScript rendering support. For many developers, this works well during early experimentation and prototyping phases.
However, Firecrawl reports a lower overall success rate (~96%) at scale, and reliability costs increase notably for JavaScript-rendered websites, which consume multiple credits per page.
This can lead to:
- Higher effective cost per successful page
- Less predictable billing for dynamic sites
- Increased friction as workloads grow
Pros
- Good reliability for developer-scale and medium workloads
- Effective handling of JS-heavy content
Cons
- Lower success rate at scale compared to Olostep
- Higher and less predictable costs for JS-rendered pages
Reliability in Practice
At a small scale, the difference between 96% and 99% success may seem negligible. At 10 million requests per month, however, that gap translates to 300,000 additional failures along with retries, delays, and added costs.
This is why teams building production systems often prioritize reliability and predictability over convenience once they begin scaling — and why many migrate from developer-centric tools to infrastructure designed explicitly for large-scale web data extraction.
4. Scalability: MVP vs Production ready project
Olostep
Olostep is explicitly designed for production-scale workloads:
- Comfortable at 200k–1M+ requests/month
- Proven scaling to 100M+ requests/month
- Infrastructure optimized for long-running, high-throughput pipelines
This is why many teams:
Start with Firecrawl → hit scale limits → migrate to Olostep
Firecrawl
Firecrawl excels at getting started quickly:
- Open-source templates
- Excellent developer onboarding
- Strong LLM-focused output quality
However, beyond a few million requests per month, teams often face:
- Cost unpredictability
- Concurrency ceilings
- Infrastructure friction
5. LLM-Ready Outputs & AI Integration
Olostep
Olostep also provides LLM-ready structured outputs through multiple endpoints:
- Markdown, HTML, or structured JSON from
scrapes - LLM extraction via prompts or parsers
- Agents that can search and summarize the web with sources blending scraping with AI planning
Best for: Mixed workflows where all of these intersect:
- Scraping
- Search extraction
- Agent automation
Firecrawl
Firecrawl excels in LLM-ready outputs:
- Outputs in standardized markdown and JSON, optimized for RAG and LLM contexts
- Schema generation and structured JSON extraction help minimize pre-processing for training data
- Native integrations with popular AI ecosystems (LangChain, LlamaIndex, etc.) streamline workflows
Best for:
- AI assistants
- Semantic search
- Vector-store ingestion
- NLP pipelines
6. Developer Experience & Use Cases
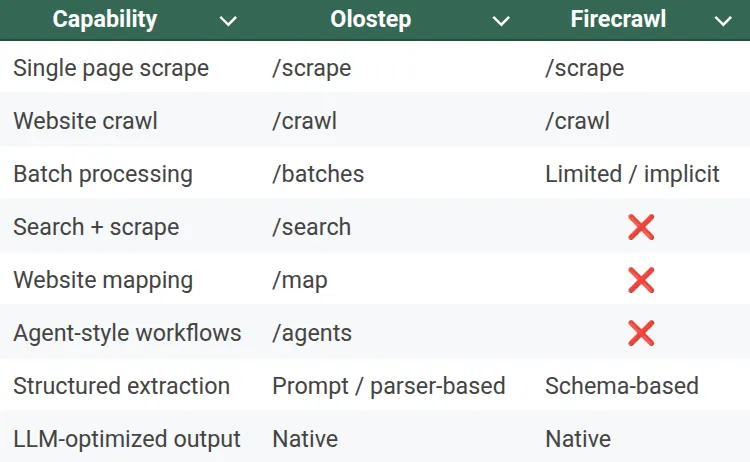
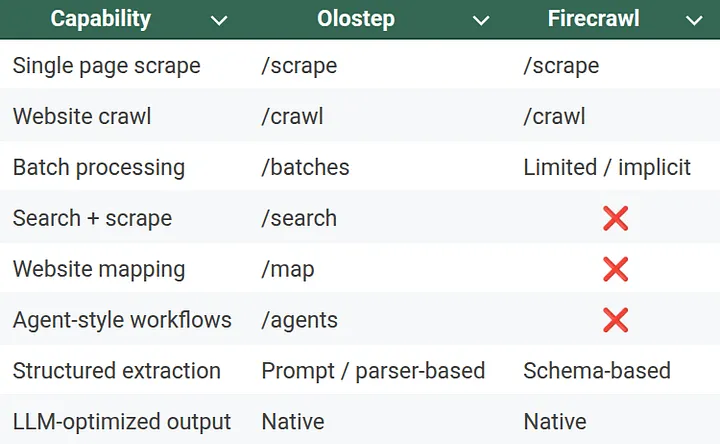
7. Endpoints Comparison
Olostep
Olostep exposes a richer set of endpoints, designed to support large-scale and multi-step workflows.
Core endpoints include:
- /scrape: Extract content from individual pages
- /crawl: Crawl entire domains with depth control
- /batches: Submit tens of thousands of URLs in one job
- /search: Query search engines and scrape results
- /map: Discover site structure and internal links
- /agents: Let AI agents browse, scrape, summarize, and reason
This design allows developers to compose workflows:
Search → Map → Crawl → Scrape → Extract → Summarize
All are using a single API provider.
Best suited for:
- E-commerce industry
- SEO industry
- AI Visibility space (GEO)
- Lead generation
- Large-scale data collection
- AI agents that “use the web”
Firecrawl
Firecrawl deliberately keeps its API surface small and opinionated.
Typical endpoints include:
- /scrape: Extract clean, structured content from a single URL
- /crawl`: Crawl an entire site and return normalized documents
- /extract (schema based extraction): Convert raw content into structured JSON for LLM pipelines
This minimalism reflects Firecrawl’s philosophy:
“Give me content that an LLM can immediately reason over.”
You don’t orchestrate workflows across many endpoints. Firecrawl abstracts that complexity internally and returns LLM-ready markdown or JSON.
Best suited for:
- RAG pipelines
- Vector database ingestion
- Knowledge base construction
- Semantic search systems
8. Which One Should You Choose?
There’s no direct answer to this question, but you can pick the right pick based on your application:
Choose Firecrawl if:
- You are a developer or a small team experimenting with ideas
- You want a fast setup and minimal configuration
- Your workload is under a few hundred thousand pages/month
- Your primary goal is clean, LLM-ready documents
Choose Olostep if:
- You are building a startup, scaleup, or enterprise product
- You need true batch scraping at a massive scale
- Predictable costs and unit economics matter
- Your workload exceeds 200k–1M+ pages/month
- You want infrastructure that won’t bottleneck growth
Conclusion
Both Olostep and Firecrawl represent the new generation of web scraping platforms, far removed from brittle, selector-based bots of the past.
Firecrawl shines as a developer-first tool: easy to adopt, tightly integrated with LLM workflows, and ideal for prototypes, internal tools, and early-stage AI projects. It lowers the barrier to entry for turning web pages into clean, LLM-ready data.
Olostep, on the other hand, is built as a production-grade web data infrastructure. With true large-scale batch processing, high concurrency, predictable pricing, and proven reliability at tens of millions of requests per month, it enables startups, scaleups, and enterprises to build real businesses on top of web data without worrying about cost blowups or scaling ceilings.
In a world where web data increasingly fuels analytics, AI systems, and autonomous agents, choosing a scraping platform is no longer just a technical decision. It’s a strategic one that defines whether your project remains an experiment or becomes a scalable, sustainable product.